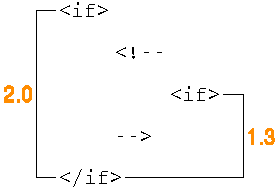|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||
|
ParsingThis chapter will describe how tags, scopes, entities and their attributes are parsed. To make it easier to understand how parsing in RXML works many examples will be provided. When RXML was redesigned to be XML compliant, many of the flaws were removed. Security issues have hopefully been removed as well as many odd quirks and behaviours. XML CompliancyTo be XML compliant, a set of requirements has to be fulfilled. At this moment the XML standard is not fully supported. Roxen is able to understand and parse all XML compliant code, but doesn't have any support for DTD-parsing. Also, the parser is very forgiving when it comes to demanding that the code follows the correct XML-syntax. The table below shows a subset of the most common differences between old RXML and the new XML compliant RXML.
Note that if a site has older RXML code it can still survive the move to the new system. By adding the RXML compatibility module the parser will understand the old syntax. RXML ParsingThe Roxen 2 RXML parser utilizes a top-down parsing approach. This means that the parser now uses preparsing instead of postparsing as in RXML 1.3. Repetitive parsing in output tags used to be a performance hog in RXML 1.3. The new parser now makes one analyze pass when doing output from a tag, instead of rescanning the output tag in every loop. This feature makes tags like <formoutput> unneccessary. The images below show some of the differences in RXML parsing between Roxen WebServer 2.1 and Roxen Challenger 1.3.
The old 1.3 RXML parser didn't recognize '<!--' comments and thus the <if> inside the comment is parsed and the first ignored. The RXML parser 2 consistently ignores code within comments. However, if the comment is a RXML comment, problems might arise while the parser are scanning the page for tags.
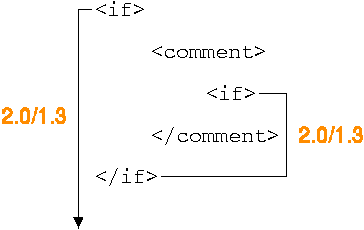
When the parser comes upon a container tag it does a scanpass, without performing any parsing, to locate the closing tag. If the parser as shown below, finds another <if> inside a RXML comment it automatically looks for its closing tag thus believing the closing tag for the first <if> is further down the page. As the RXML parser 2 can't find the last <if> tag it decides there are unmatching tags in the code and returns an unbalanced tag error message.
When the parser scans a page for tags it automatically evaluates the tag that it recognizes and stores the results for later use. Recognized tags are tags that are registered within the parser, mostly RXML-tags. Tags which the parser doesn't recognize, like HTML-tags, won't be parsed but their attributes will be stored. The 1.3 parser however, isn't that smart and will declare all unknown tags as text and hence the <if> tag will be found and parsed. |
|||||||||||||||